
TLDR ⚡
- What you will learn: How machine learning can predict Solana transaction compute usage before execution using real on-chain data.
- Why it matters: Accurate CU prediction enables smarter transaction prioritization, fairer fee markets, and more efficient block packing directly improving network performance.
- Exo Edge: Instead of static heuristics, we treat compute consumption as a learnable network signal, showing that validator intelligence can be data-driven and deployed in real time.
Introduction
Every transaction on Solana declares a compute unit (CU) budget upfront. Validators use this information to prioritize transactions, favoring those that offer higher fees relative to their requested compute (fee-per-CU).
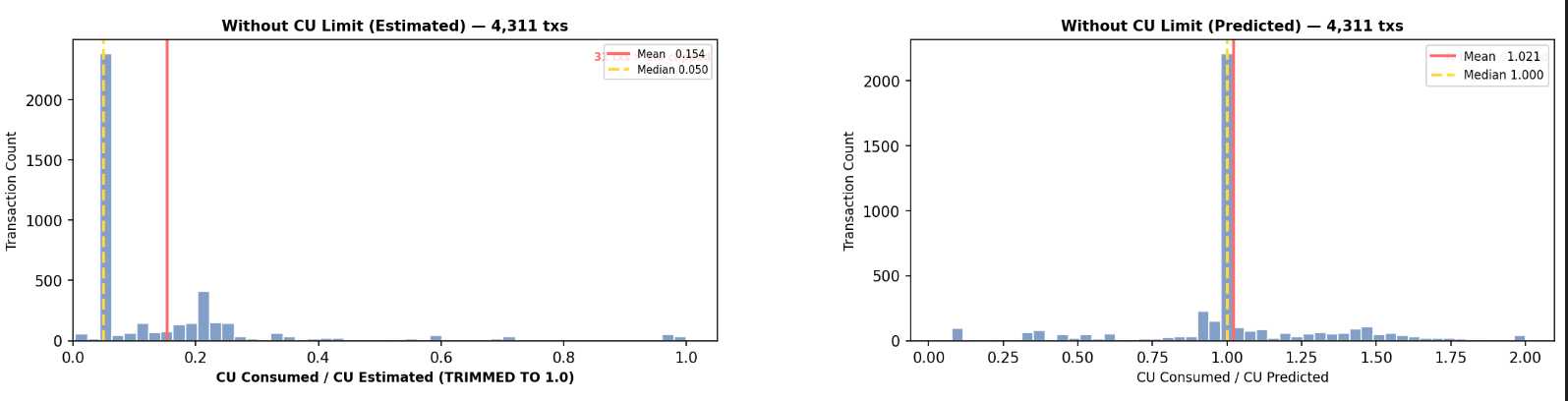
In practice, however, requested compute rarely matches actual compute consumed. CU usage varies widely depending on the program being executed, the instruction inputs, and what accounts are accessed during runtime. As a result, validators make decisions using estimates that are often inaccurate (see diagram below).
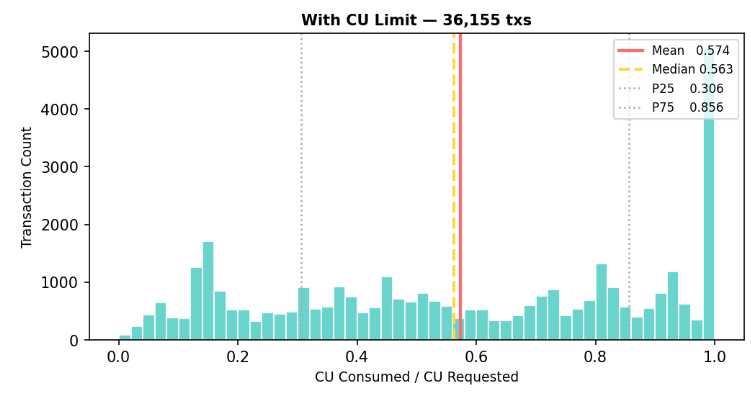
This mismatch introduces inefficiency. Transactions may be prioritized incorrectly, valuable block space can be wasted, and fee markets become less reflective of real resource usage.
What if compute consumption could be predicted before execution, not through fixed heuristics, but by learning patterns directly from real on-chain activity?
In this work, we built a proof-of-concept system that ingests Solana transaction data, extracts instruction-level features, and trains machine learning models to predict compute usage with ~68% accuracy.
The discussion is divided into three sections:
- The Problem: CU Predictions Are Unreliable
- Why This Matters
- Why AI Is a Good Fit
- The POC Approach
The Problem: CU Predictions Are Unreliable
Declaring compute units is optional on Solana, and both cases when CUs are specified and not specified introduce problems.
When CUs are specified
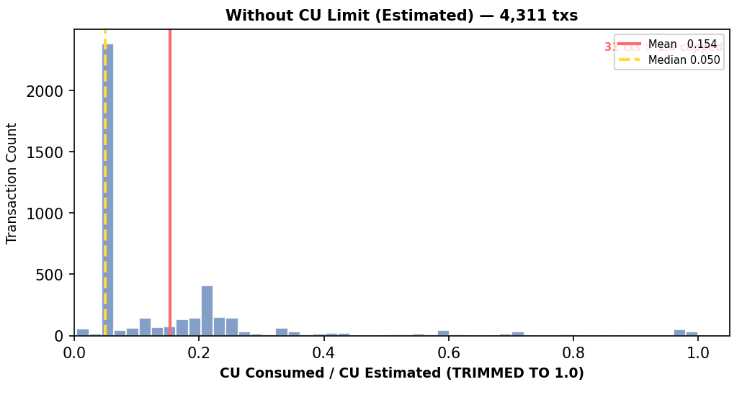
Even when transactions declare a compute budget, the requested value often differs substantially from actual consumption. Developers typically overestimate to avoid transaction failure.
Because of this variance, validator’s transaction scheduler cannot reliably use requested CUs to calculate true fee-per-CU.
When CUs are not specified
If no compute budget is declared, validators fall back on simple heuristics:
- Built-in programs: ~3,000 CU per instruction
- Custom programs: ~200,000 CU per instruction
Around 10–15% of transactions rely on these defaults.
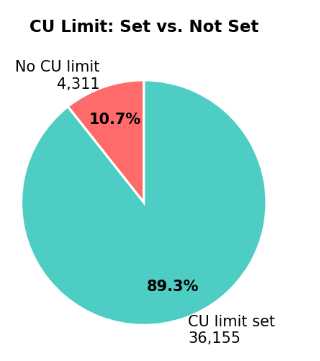
These estimates are extremely coarse. Real on-chain data shows compute usage varies dramatically even within the same program, causing systematic overestimation.
The consequence is straightforward:
Transaction scheduler make wrong prioritization decisions.
High-value transactions may be under-prioritized, block capacity is used inefficiently, and fee markets cannot accurately reflect actual computational cost.
Why This Matters
Accurate CU prediction maps directly to network performance:
- Better prioritization: Sort transactions by true resource cost, not estimated (see figure 4)
- Fair pricing: Validators can charge fees proportional to actual resource consumption
- Tighter block packing: Fill blocks more efficiently by replacing heuristics with accurate predictions.
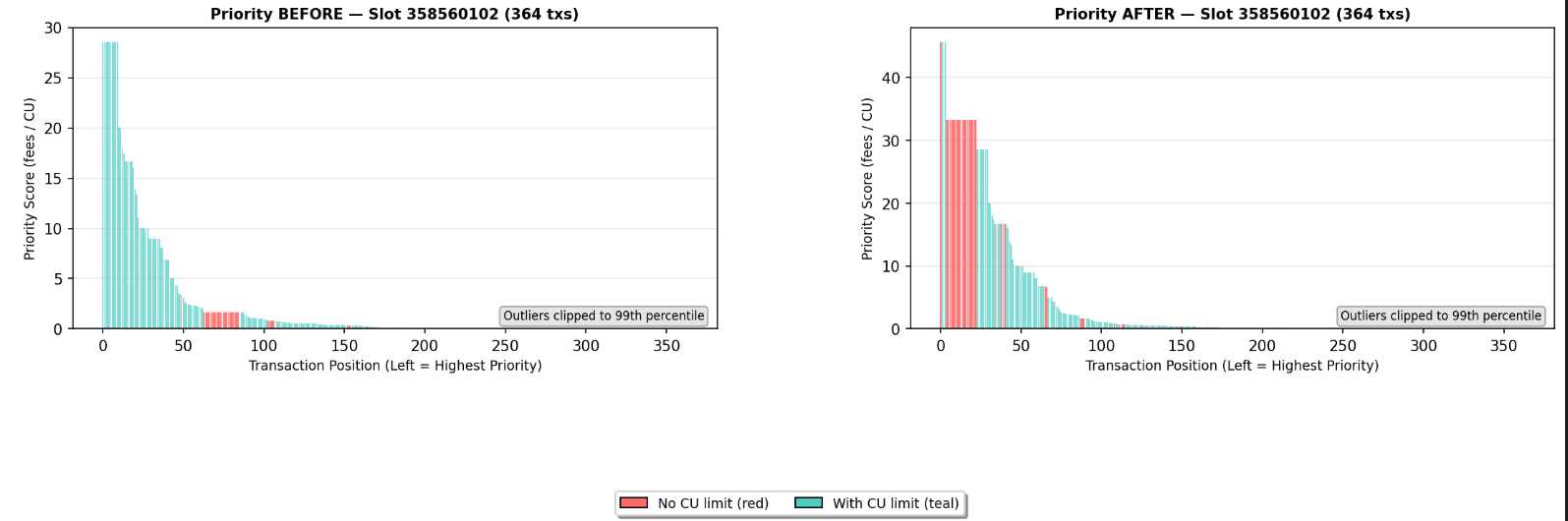
This aligns with Solana's broader mission: real-time systems at scale require intelligence embedded into the network, not bolted on afterwards.
Why AI is a Good Fit
Machine learning excels at these kind of problems:
High Variance: CU consumption isn't linear. It is program-specific and data-dependent. Traditional rules can't capture this complexity. Gradient boosting (XGBoost) is built for exactly this: tabular data with nonlinear relationships.
Data-Driven Learning: Rather than hand-code heuristics, we learn directly from real transactions. This automatically adapts as Solana's program ecosystem evolves.
The POC Approach
To test whether CU consumption could be predicted reliably, we built a proof-of-concept pipeline that learns directly from real on-chain execution data.
The system follows three stages: data ingestion → model training → real-time prediction.
Phase 1: Data Collection (Rust + Firehose)
We stream transactions in real time using Solana’s Firehose gRPC service and extract execution-level signals for each instruction.
For every instruction executed, we record:
- Program ID — identifies which program performed computation
- Instruction data
- First 8 bytes isolated as the program discriminator
- Remaining bytes captured as raw input parameters
- Actual compute units consumed, parsed directly from execution logs
Phase 2: ML Training (Python)
Once transaction data is collected, features are extracted to train the Machine Learning model.
Feature Encoding
- Program ID → categorical encoding (mapped into numeric representations)
- Instruction data → byte-level numerical features (0–255)
- Total feature vector: 521 features per instruction
We trained a gradient-boosted decision tree model using XGBoost, chosen for its strengths in:
- nonlinear relationships
- heterogeneous tabular data
- fast inference performance
Phase 3: Prediction & Evaluation
Load trained models, predict CU for new transactions, analyze residuals and prediction accuracy.
POC Results
The model was trained on approximately 108,000 Solana transactions, with performance evaluated on a held-out 20% test set.
Results show substantial improvement over existing heuristics, especially for transactions that do not explicitly declare compute budgets.
Key Outcomes
Variance explained (R²): 67.9%
(heuristic estimates explain ~40% or less)
Average prediction error: ±10,914 CU
(vs. ±35,000+ CU using fixed rules)
Inference latency: sub-millisecond
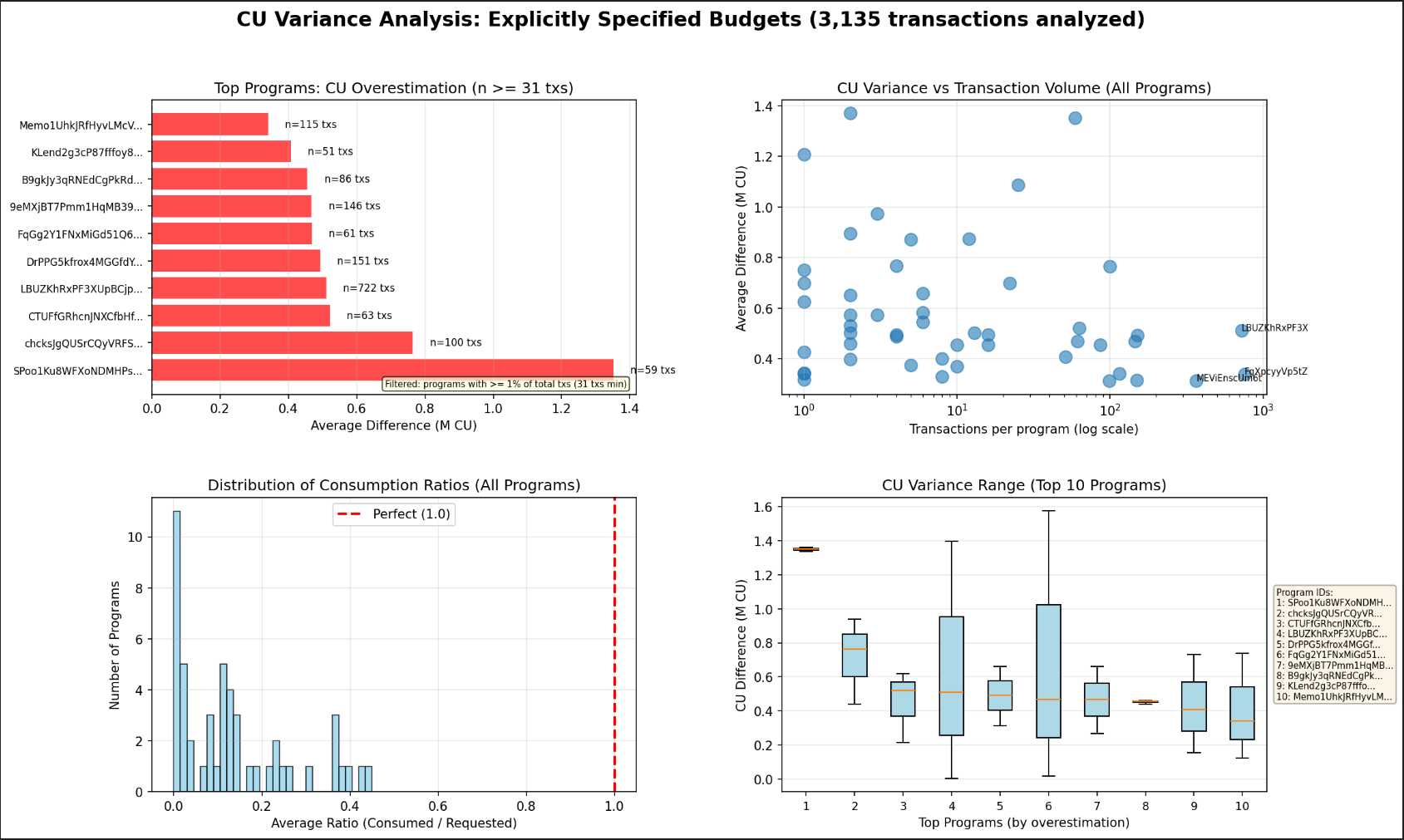
CU Variance Analysis
Another useful perspective is analyzing compute unit (CU) variance — the gap between requested and actual compute consumption. This helps answer questions such as:
- What is the average difference between requested and consumed CUs?
- Which programs consistently over-request compute, and how frequently do they appear in network activity?
You can run the below analysis using analyze_explicit_cu.py
Why Not 100% Accuracy?
Solana compute consumption contains inherent uncertainty that cannot be fully captured from instruction inputs alone.
Key hidden variables include:
- Program and Accounts state: dynamic on-chain data influences computation paths
- Runtime branching behavior: loops and conditional logic vary per execution
These factors are only known during execution, not beforehand.
Next Steps
This proof-of-concept demonstrates that CU prediction is both feasible and practical. The natural progression is integrating intelligence directly into validator workflows.
Predict CU usage during leader slots or use block production simulations as a final testament and improve transaction prioritization in real time.
References
- POC Repository: https://github.com/Huzaifa696/cu_estimator
- Anza blog on CU: https://www.anza.xyz/blog/why-solana-transaction-costs-and-compute-units-matter-for-developers
- Solana RFP: Objective 2 (Network Intelligence & Performance) – this work addresses validator-facing tools
- XGBoost Docs: https://xgboost.readthedocs.io/